是个屁的邂逅.为什么这个lab做的时间比cachelab要晚呢?主要是我看小土刀只做了7个lab,然后我又不想看chapter4,导读也说不用看我直接就跳了.谁知道做完cachelab后我把做好的lab一上传,发现我库里有8个lab,然后找到了lab assignment,原来我直接把这个lab给忽略了,所以呀,现在要掉头回来干这个lab.
照例给出一些链接,减少大家搜资料的时间成本.(来源于cmu)
总览
我们要做Part A,B,C,其中A和B是C的基础,pdf里面说A和B比较简单,C比较难
Y86_64常用指令集
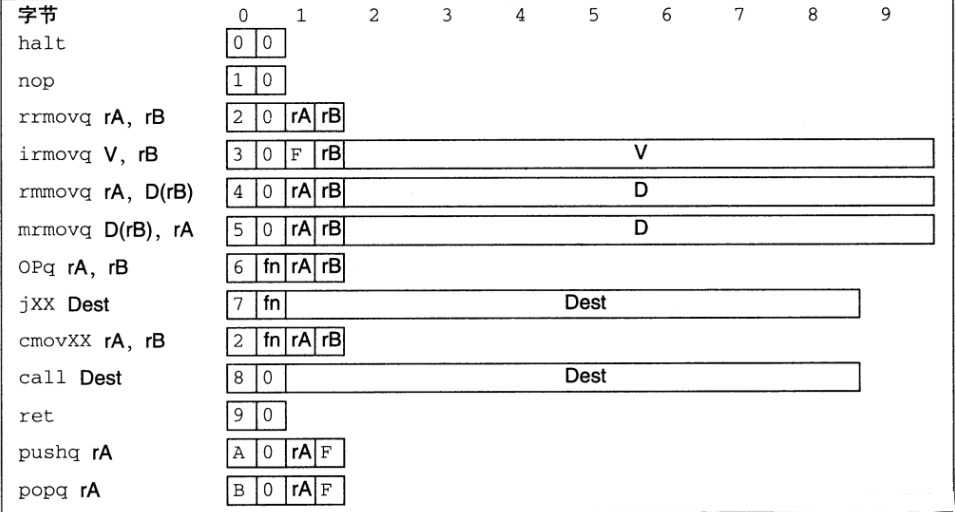
- irmovq指令表示将一个立即数存进一个寄存器中
- rrmovq指令表示将一个寄存器中的值存进一个寄存器中
- rmmovq指令表示将一个寄存器中的值存进一个内存地址所对应的内存中
- mrmovq指令表示将一个内存中的值存进一个寄存器中
所以我们要注意,没有mmmovq,不能将内存中的值和内存中的值进行直接转移,需要拿寄存器存起来。
Part A
一开始还在纳闷为啥part_A没有教程,自己一做,发现确实简单,就是一些指令的运用热身罢了。坚持坚持,都能做出来的啦!
Sum.ys
RULES:
Write a Y86-64 program sum.ys that iteratively sums the elements of a linked list. Your program should consist of some code that sets up the stack structure, invokes a function, and then halts.
In this case,the function should be Y86-64 code for a function (sum list) that is functionally equivalent to the C sum list function in Figure 1.写一个Y86-64程序sum.ys,迭代地对链表的元素求和。你的程序应该由一些代码组成,这些代码设置堆栈结构,调用函数,然后停止。在这种情况下,该函数应该是Y86-64代码,用于在功能上等同于图1中的C sum list函数的函数(sum list)。使用以下三元素列表测试程序:
sum list
long sum_list(list_ptr ls)
{
long val = 0;
while (ls) {
val += ls->val;
ls = ls->next;
}
return val;
}所以我们就是仿照CSAPP课本中文版p252页的完整Y86-64汇编代码流程翻译Sum_List函数,汇编代码如下
# Execution begins at address 0
.pos 0
irmovq stack, %rsp
call main
halt
# Sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
# get main
main:
irmovq ele1, %rdi
call sum_list # sum(list_ptr ls)
ret
# long sum_list(list_ptr ls)
# start in %rdi
sum_list:
xorq %rax,%rax #rax-->sum_list=0
andq %rdi ,%rdi # test
jmp test
loop:
mrmovq (%rdi),%rsi
addq %rsi,%rax
mrmovq 8(%rdi),%rdi # rdi--->next
andq %rdi,%rdi # test rdi
test:
jne loop # rdi==0 ret
ret
.pos 0x200
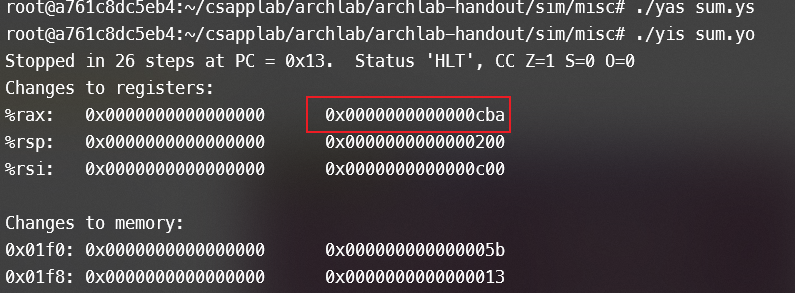
stack:然后使用yas和yis进行测试,若%rax==0xcba则成功!
rsum.ys
rsum.ys: Recursively sum linked list elements
Write a Y86-64 program rsum.ys that recursively sums the elements of a linked list. This code should be similar to the code in sum.ys, except that it should use a function rsum list that recursively sums a
list of numbers, as shown with the C function rsum list in Figure 1. Test your program using the same three-element list you used for testing list.ys.编写一个Y86-64程序rsum.ys,递归地对链表的元素求和。这段代码应该与sum.ys中的代码类似,只是它应该使用一个函数rsum list来递归地对一个数字列表求和,如图1中的C函数rsum list所示。
rsum_list
long rsum_list(list_ptr ls)
{
if (!ls)
return 0;
else {
long val = ls->val;
long rest = rsum_list(ls->next);
return val + rest;
}
}递归操作由Bomblab的经验可以知道,肯定需要使用pushq和popq操作,递归调用即可,判断一下地址为0就是递归尽头就好了,简单!~~
# rsum.ys: Recursively sum linked list elements
# author Vite
# Execution begins at address 0
.pos 0
irmovq stack, %rsp
call main
halt
# Sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
# get main
main:
irmovq ele1, %rdi
call rsum_list
ret
rsum_list:
andq %rdi ,%rdi
je return
mrmovq (%rdi),%rsi
mrmovq 8(%rdi),%rdi
pushq %rsi
call rsum_list
popq %rsi
addq %rsi,%rax
ret
return:
irmovq $0x0, %rax
ret
.pos 0x200
stack:
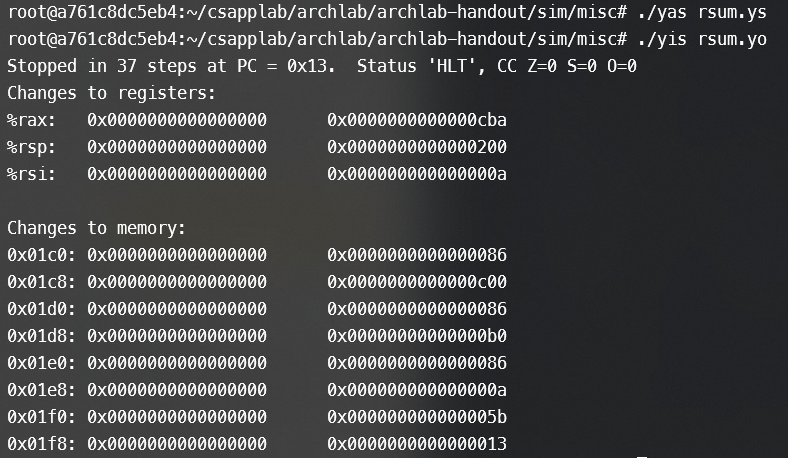
写完后测试提交,$rax的值正确!
copy.ys
copy.ys: Copy a source block to a destination block
Write a program (copy.ys) that copies a block of words from one part of memory to another (non-overlapping area) area of memory, computing the checksum (Xor) of all the words copied. Your program should consist of code that sets up a stack frame, invokes a function copy block, and then halts. The function should be functionally equivalent to the C function copy block shown in Figure 1. Test your program using the following three-element source and destination blocks:编写一个程序(copy.ys),将一个字块从内存的一部分复制到内存的另一个(非重叠区域)区域,计算所有复制的字的校验和(Xor)。你的程序应该由建立堆栈框架、调用函数复制块、然后停止的代码组成。该函数在功能上应等同于图1所示的C函数复制块。
copy_block
long copy_block(long *src, long *dest, long len)
{
long result = 0;
while (len > 0) {
long val = *src++;
*dest++ = val;
result ^= val;
len--;
}
return result;
}大致思路:
取出src[0]的值,丢到dest[0]中,把%rax的值xor val,然后把len–,每次进入循环要记得判断len,要是len=0就退出循环
然后开始仿照前两个函数构建汇编代码,注意语句,反正写的错了他也会告诉你错了,再改就是了
故最终的汇编代码为:
# copy.ys: Copy a source block to a destination block
# autor Vite
# exe begins in address 0
.pos 0
irmovq stack , %rsp
call main
halt
#Sample linked
.align 8
# Source block
src:
.quad 0x00a
.quad 0x0b0
.quad 0xc00
# Destination block
dest:
.quad 0x111
.quad 0x222
.quad 0x333
# make main
main:
irmovq src , %rdi
irmovq dest, %rsi
irmovq $3 , %rdx
xorq %rax,%rax
call copy_block
ret
copy_block:
andq %rdx,%rdx
je return
mrmovq (%rdi), %r8
rmmovq %r8, (%rsi)
xorq %r8, %rax
irmovq $8 ,%r8
addq %r8,%rdi
addq %r8,%rsi
irmovq $1, %r8
subq %r8 ,%rdx
call copy_block
return :
ret
.pos 0x200
stack:
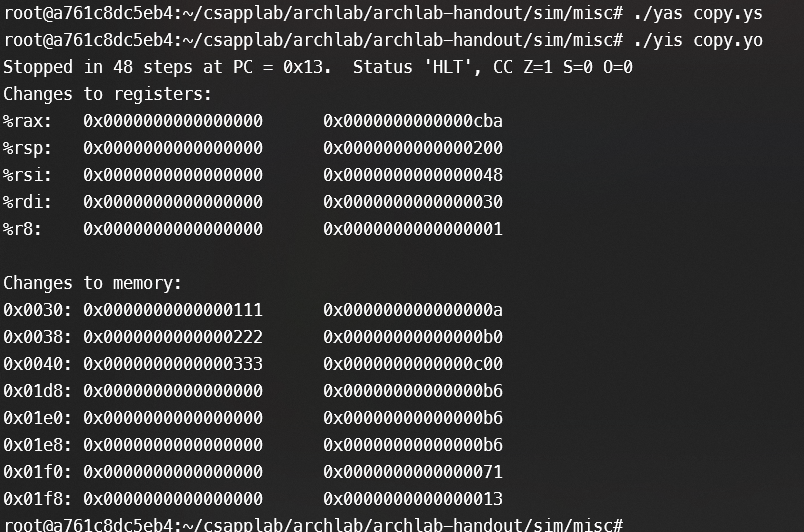
简单教一下,看下%rax中存的返回值,再看下memory中的改变值,类似于下图,完成题目要求,通关Part_A!
Part B
前置知识:
概要:SEQ课本中文版P278 4.3SEQ的实现,图4-27往后。
直接对着SEQ的流程图进行模仿,挨个把IADDQ这个关键字丢进去。然后编译运行
Your task in Part B is to extend the SEQ processor to support the iaddq, described in Homework problems 4.51 and 4.52. To add this instructions, you will modify the file seq-full.hcl, which implements the version of SEQ described in the CS:APP3e textbook. In addition, it contains declarations of some constants that you will need for your solution.
您在B部分的任务是扩展SEQ处理器以支持iaddq,如作业问题4.51和4.52所述。要添加此说明,您需要修改seq-full.hcl文件,该文件实现了CS:APP 3e教科书中描述的SEQ版本。此外,它还包含解决方案所需的一些常数的声明。
4.51:练习题4.3介绍了iaddq 指令,即将立即数与寄存器相加。描述实现该指令所执行的计算。参考irmovq 和 OPq 指令的计算(图 4-18)
4.52:文件seq-full.hcl包含SEQ的HCL描述,并将常数IIADDQ声明为十六进制值C,也就是 iaddq的指令代码.修改实现iaddq指令的控制逻辑块的HCL描述,就像练习题4.3和家庭作业4.51中描述的那样.可以参考实验资料获得如何为你的解答生成模拟器以及如何测试模拟器的指导。
图 4-18 给出了对 OPq( 整数和逻辑运算)、rrmovq( 寄存器-寄存器传送)和 irmovq( 立即数-寄存器传送)类型的指令所需的处理。让我们先来考虑一下整数操作。回顾图4-2,可以看到我们小心地选择了指令编码,这样四个整数操作 (addq 、subq 、andq 和 xorq) 都有相同的 icode 值.我们可以以相同的步骤顺序来处理它们,除了 ALU 计算必须根据ifun中编码的具体的指令操作来设定。
iaddq指令如下:

取指阶段:从PC中取
- 取icode:ifun <—M
1[PC] - 取rA:rB<—M
1[PC+1] - 取ValC<—M
8[PC+2] - 更新Valp<–PC+10
译码阶段:ValB<—R[rB]
执行阶段:ValE <– ValB-ValC
写回阶段:R[rB]<—ValE
更新PC: PC<—Valp
寄存器 ID dstE 表明写端口E 的目的寄存器,计算出来的值 valE 将放在那里。
操作
需要更新的部分有以下几部分:
Fetch Stage
- instr_valid=icode in
该信号判断是否为合法指令
- need——regids
需要读取寄存器rb
- need_valc
需要立即数valC
################ Fetch Stage ###################################
bool instr_valid = icode in
{ INOP, IHALT, IRRMOVQ, IIRMOVQ, IRMMOVQ, IMRMOVQ,
IOPQ, IJXX, ICALL, IRET, IPUSHQ, IPOPQ, IIADDQ };
# Does fetched instruction require a regid byte?获取的指令是否需要regid字节?
bool need_regids =
icode in { IRRMOVQ, IOPQ, IPUSHQ, IPOPQ,
IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ};
# Does fetched instruction require a constant word?
bool need_valC =
icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IJXX, ICALL,IIADDQ };
Decode Stage
- srcB:rB
- dstE
## What register should be used as the B source?
word srcB = [
icode in { IOPQ, IRMMOVQ, IMRMOVQ,IIADDQ } : rB;
icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP;
1 : RNONE; # Don't need register
];
## What register should be used as the E destination?
word dstE = [
icode in { IRRMOVQ } && Cnd : rB;
icode in { IIRMOVQ, IOPQ,IIADDQ} : rB;
icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP;
1 : RNONE; # Don't write any register
];
Execute Stage
- aluA:valC
- aluB:valB
- set_cc
################ Execute Stage ###################################
## Select input A to ALU
word aluA = [
icode in { IRRMOVQ, IOPQ } : valA;
icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ,IIADDQ } : valC;
icode in { ICALL, IPUSHQ } : -8;
icode in { IRET, IPOPQ } : 8;
# Other instructions don't need ALU
];
## Select input B to ALU
word aluB = [
icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL,
IPUSHQ, IRET, IPOPQ,IIADDQ } : valB;
icode in { IRRMOVQ, IIRMOVQ } : 0;
# Other instructions don't need ALU
];
## Should the condition codes be updated?
bool set_cc = icode in { IOPQ, IIADDQ};Memory Stage && PC update
==none==
标程
以下是完整代码:
#/* $begin seq-all-hcl */
####################################################################
# HCL Description of Control for Single Cycle Y86-64 Processor SEQ #
# Copyright (C) Randal E. Bryant, David R. O'Hallaron, 2010 #
####################################################################
## Your task is to implement the iaddq instruction
## The file contains a declaration of the icodes
## for iaddq (IIADDQ)
## Your job is to add the rest of the logic to make it work
####################################################################
# C Include's. Don't alter these #不要改变这些 #
####################################################################
quote '#include <stdio.h>'
quote '#include "isa.h"'
quote '#include "sim.h"'
quote 'int sim_main(int argc, char *argv[]);'
quote 'word_t gen_pc(){return 0;}'
quote 'int main(int argc, char *argv[])'
quote ' {plusmode=0;return sim_main(argc,argv);}'
####################################################################
# Declarations. Do not change/remove/delete any of these #
####################################################################
##### Symbolic representation of Y86-64 Instruction Codes Y86-64指令码的符号表示 #############
wordsig INOP 'I_NOP'
wordsig IHALT 'I_HALT'
wordsig IRRMOVQ 'I_RRMOVQ'
wordsig IIRMOVQ 'I_IRMOVQ'
wordsig IRMMOVQ 'I_RMMOVQ'
wordsig IMRMOVQ 'I_MRMOVQ'
wordsig IOPQ 'I_ALU'
wordsig IJXX 'I_JMP'
wordsig ICALL 'I_CALL'
wordsig IRET 'I_RET'
wordsig IPUSHQ 'I_PUSHQ'
wordsig IPOPQ 'I_POPQ'
# Instruction code for iaddq instruction
wordsig IIADDQ 'I_IADDQ'
##### Symbolic represenations of Y86-64 function codes Y86-64函数代码的符号表示 #####
wordsig FNONE 'F_NONE' # Default function code
##### Symbolic representation of Y86-64 Registers referenced explicitly明确引用的Y86-64寄存器的符号表示 #####
wordsig RRSP 'REG_RSP' # Stack Pointer
wordsig RNONE 'REG_NONE' # Special value indicating "no register"
##### ALU Functions referenced explicitly ALU函数显式引用 #####
wordsig ALUADD 'A_ADD' # ALU should add its arguments
##### Possible instruction status values 可能的指令状态值 #####
wordsig SAOK 'STAT_AOK' # Normal execution
wordsig SADR 'STAT_ADR' # Invalid memory address
wordsig SINS 'STAT_INS' # Invalid instruction
wordsig SHLT 'STAT_HLT' # Halt instruction encountered
##### Signals that can be referenced by control logic控制逻辑可参考的信号 ####################
##### Fetch stage inputs #####
wordsig pc 'pc' # Program counter
##### Fetch stage computations 获取阶段计算 #####
wordsig imem_icode 'imem_icode' # icode field from instruction memory 来自指令存储器的icode字段
wordsig imem_ifun 'imem_ifun' # ifun field from instruction memory来自指令存储器的ifun字段
wordsig icode 'icode' # Instruction control code指令控制码
wordsig ifun 'ifun' # Instruction function指导作用
wordsig rA 'ra' # rA field from instruction指令中的rA字段
wordsig rB 'rb' # rB field from instruction
wordsig valC 'valc' # Constant from instruction指令中常数
wordsig valP 'valp' # Address of following instruction
boolsig imem_error 'imem_error' # Error signal from instruction memory
boolsig instr_valid 'instr_valid' # Is fetched instruction valid?
##### Decode stage computations #####
wordsig valA 'vala' # Value from register A port
wordsig valB 'valb' # Value from register B port
##### Execute stage computations #####
wordsig valE 'vale' # Value computed by ALU
boolsig Cnd 'cond' # Branch test
##### Memory stage computations #####
wordsig valM 'valm' # Value read from memory
boolsig dmem_error 'dmem_error' # Error signal from data memory
####################################################################
# Control Signal Definitions. 控制信号定义 #
####################################################################
################ Fetch Stage ###################################
# Determine instruction code
word icode = [
imem_error: INOP;
1: imem_icode; # Default: get from instruction memory
];
# Determine instruction function
word ifun = [
imem_error: FNONE;
1: imem_ifun; # Default: get from instruction memory
];
bool instr_valid = icode in
{ INOP, IHALT, IRRMOVQ, IIRMOVQ, IRMMOVQ, IMRMOVQ,
IOPQ, IJXX, ICALL, IRET, IPUSHQ, IPOPQ, IIADDQ };
# Does fetched instruction require a regid byte?获取的指令是否需要regid字节?
bool need_regids =
icode in { IRRMOVQ, IOPQ, IPUSHQ, IPOPQ,
IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ};
# Does fetched instruction require a constant word?
bool need_valC =
icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IJXX, ICALL,IIADDQ };
################ Decode Stage ###################################
## What register should be used as the A source?哪个寄存器应该用作A源
word srcA = [
icode in { IRRMOVQ, IRMMOVQ, IOPQ, IPUSHQ } : rA;
icode in { IPOPQ, IRET } : RRSP;
1 : RNONE; # Don't need register
];
## What register should be used as the B source?
word srcB = [
icode in { IOPQ, IRMMOVQ, IMRMOVQ,IIADDQ } : rB;
icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP;
1 : RNONE; # Don't need register
];
## What register should be used as the E destination?
word dstE = [
icode in { IRRMOVQ } && Cnd : rB;
icode in { IIRMOVQ, IOPQ,IIADDQ} : rB;
icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP;
1 : RNONE; # Don't write any register
];
## What register should be used as the M destination?
word dstM = [
icode in { IMRMOVQ, IPOPQ } : rA;
1 : RNONE; # Don't write any register
];
################ Execute Stage ###################################
## Select input A to ALU
word aluA = [
icode in { IRRMOVQ, IOPQ } : valA;
icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ,IIADDQ } : valC;
icode in { ICALL, IPUSHQ } : -8;
icode in { IRET, IPOPQ } : 8;
# Other instructions don't need ALU
];
## Select input B to ALU
word aluB = [
icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL,
IPUSHQ, IRET, IPOPQ,IIADDQ } : valB;
icode in { IRRMOVQ, IIRMOVQ } : 0;
# Other instructions don't need ALU
];
## Set the ALU function
word alufun = [
icode == IOPQ : ifun;
1 : ALUADD;
];
## Should the condition codes be updated?
bool set_cc = icode in { IOPQ, IIADDQ};
################ Memory Stage ###################################
## Set read control signal
bool mem_read = icode in { IMRMOVQ, IPOPQ, IRET };
## Set write control signal
bool mem_write = icode in { IRMMOVQ, IPUSHQ, ICALL};
## Select memory address
word mem_addr = [
icode in { IRMMOVQ, IPUSHQ, ICALL, IMRMOVQ} : valE;
icode in { IPOPQ, IRET } : valA;
# Other instructions don't need address
];
## Select memory input data
word mem_data = [
# Value from register
icode in { IRMMOVQ, IPUSHQ } : valA;
# Return PC
icode == ICALL : valP;
# Default: Don't write anything
];
## Determine instruction status确定指令状态
word Stat = [
imem_error || dmem_error : SADR;
!instr_valid: SINS;
icode == IHALT : SHLT;
1 : SAOK;
];
################ Program Counter Update ############################
## What address should instruction be fetched at
word new_pc = [
# Call. Use instruction constant
icode == ICALL : valC;
# Taken branch. Use instruction constant
icode == IJXX && Cnd : valC;
# Completion of RET instruction. Use value from stack
icode == IRET : valM;
# Default: Use incremented PC
1 : valP;
];
#/* $end seq-all-hcl */
测试
修改完后需要通过该HCL文件构建SEQ仿真器(ssim)的新实例,然后对其进行测试:
- 根据
seq-full.hcl文件构建新的仿真器
cd到seq文件夹中输入以下命令:
make VERSION=full**注意:**如果你不含有Tcl/Tk,需要在Makefile中将对应行注释掉
**注意:**若出现以下问题:
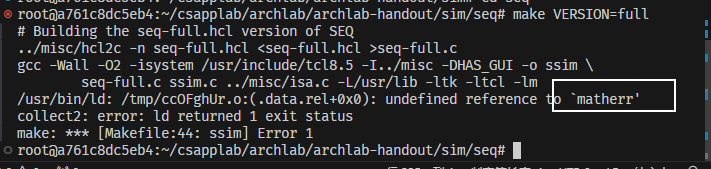
解决方法:在seq文件夹中打开ssim.c,ctrl+f查询matherr,将相关两行代码注释掉,继续执行make VERSION=full

- 在小的Y86-64程序中测试你的方法
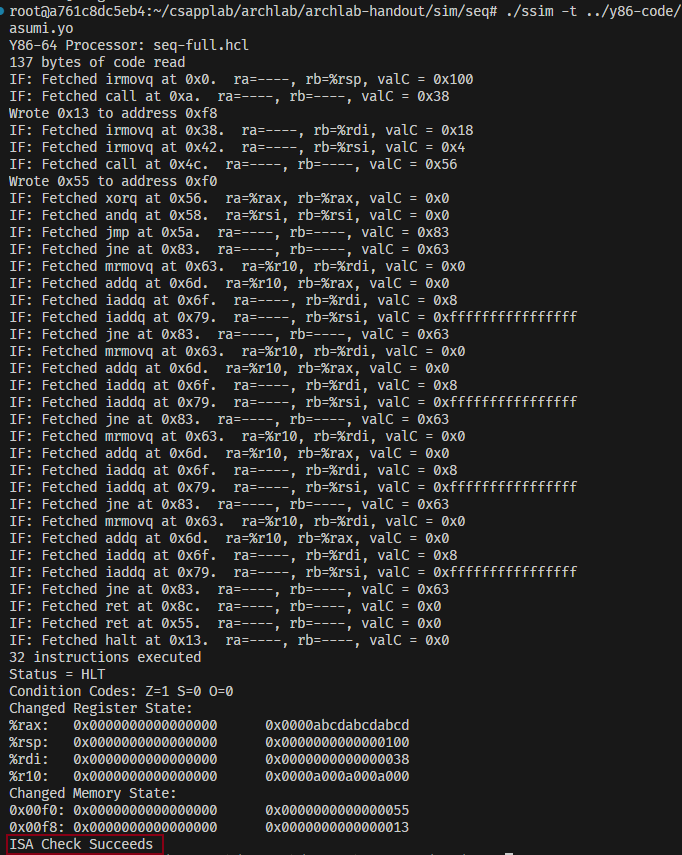
./ssim -t ../y86-code/asumi.yo如果失败了,还要重新修改你的实现,若成功则类似于下图所示:
- 使用基准程序来测试你的方法
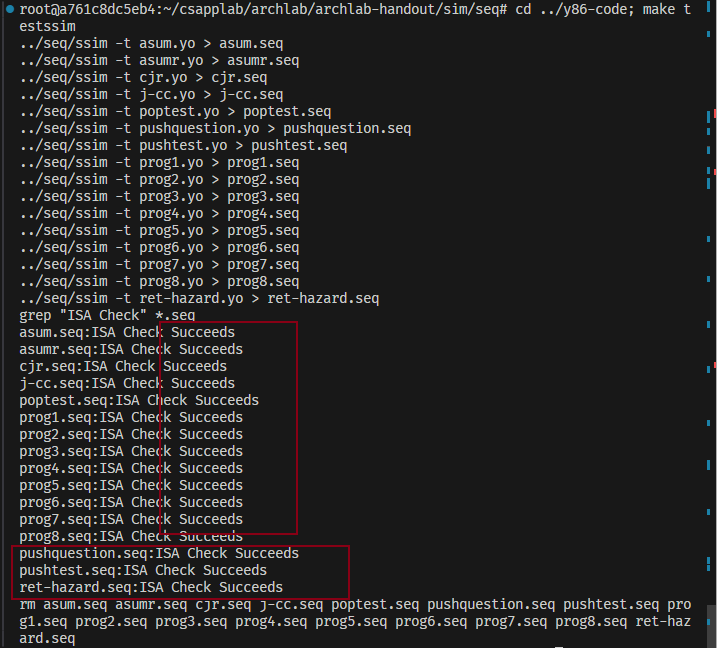
cd ../y86-code; make testssim这将在基准程序上运行ssim,并通过将结果处理器状态与高级ISA仿真中的状态进行比较来检查正确性。注意,这些程序均未测试添加的指令,只是确保你的方法没有为原始说明注入错误。
- 一旦可以正确执行基准测试程序,则应在
../ptest中运行大量的回归测试
- 测试除了
iaddq以外的所有指令
cd ../ptest; make SIM=../seq/ssim出现了大量的warning不用担心,关注结果即可!
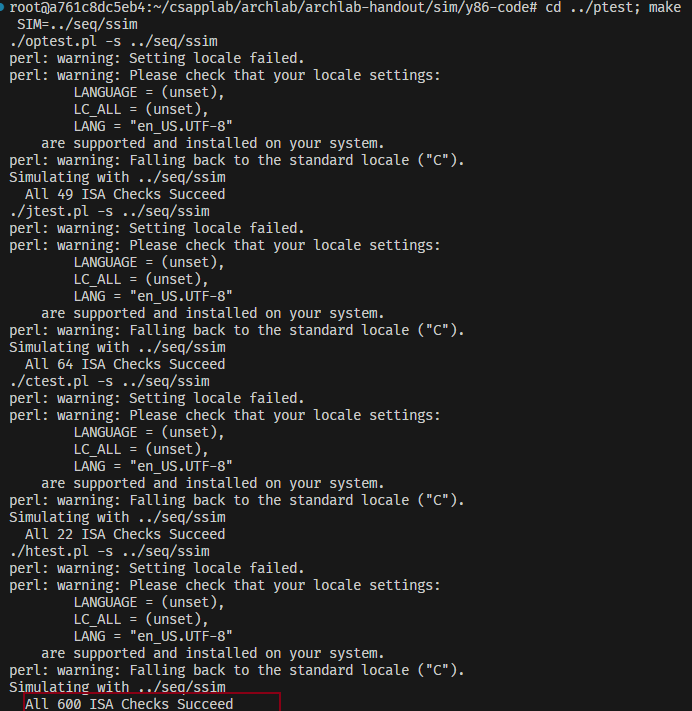
- 测试我们实现的
iaddq指令
cd ../ptest; make SIM=../seq/ssim TFLAGS=-i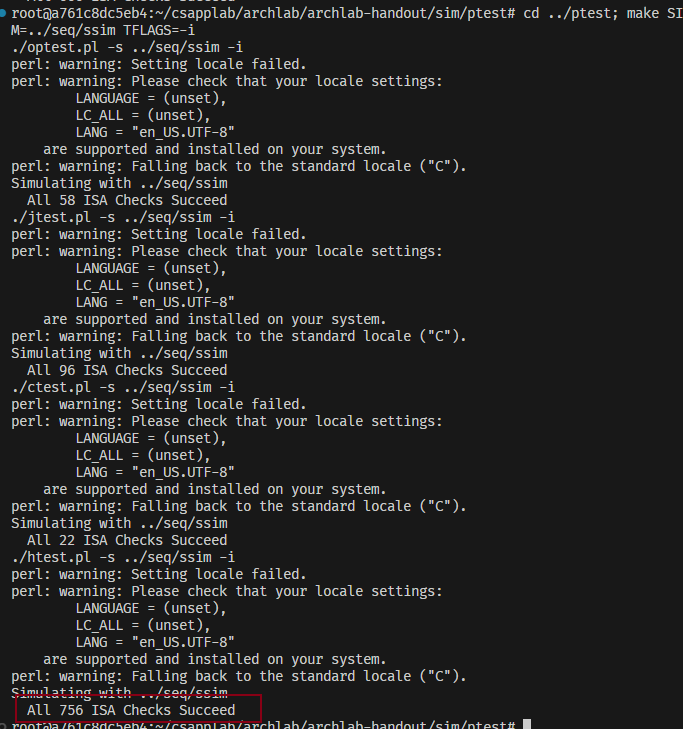
若关键信息都Succeed那么就代表这个对于IADDQ的描述是正确的,Part_B通关!
这个warning烦了我两天,乱搞之中不知道搞了什么,连make都失败了,索性重头解压tar做了一遍
Part C
总览:
这部分工作目录在
sim/pipe下,题目给定了 ncopy 函数的 C 代码,这个函数和 Part A 的第三题差不多,将 src 数组复制到 dest 数组,并返回数组中的正数的总数。题目还给定了这个函数的 Y86-64 代码,并在文件pipe-full.hcl中实现了一个包含IIADDQ常量的 PIPE 。题目要求修改 [ncopy.ys]和 [pipe-full.hcl] ,使得ncopy.ys运行得尽可能快。
测试命令(参考官方文档第八页):
1、保证代码正确:
./correctness.pl2、保证模拟器正确
cd ../y86-code; make testpsim
cd ../ptest; make SIM=../pipe/psim TFLAGS=-i3、保证二者结合正确
./correctness.pl -p通过了上面的测试,才能保证代码和模拟器都OK。
使用../misc/yas ncopy.ys 生成ncopy.yo
使用./check-len.pl < ncopy.yo 检测长度
使用 unix> make VERSION=full 重建测试环境;
使用make drivers 生成ncopy.ys的测试程序
使用 unix> ./psim -t sdriver.yo 和 unix> ./psim -t ldriver.yo 分别测试small 4-element array和larger 63-element array
使用 unix> ./correctness.pl 测试 ncopy.ys 代码是否正确;
使用 unix> ./benchmark.pl 自动测试得到平均 CPE 。
最初用给定的代码测试得到平均 CPE 约为 15.18 。这里要拿满分平均 CPE 应在 7.5 以下。
IADDQ优化
在hcl中仿照part B增加IADDQ指令,然后再ncopy.ys中把addq都改成IADDQ指令,删除不必要的将立即数放入寄存器的指令,得到CPE为12.7.
代码大致如下
# You can modify this portion
# Loop header
xorq %rax,%rax # count = 0;
andq %rdx,%rdx # len <= 0?
jle Done # if so, goto Done:
Loop:
mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Npos # if so, goto Npos:
iaddq $1, %rax # count++
Npos:
iaddq $-1, %rdx # len--
iaddq $8, %rdi # src++
iaddq $8, %rsi # dst++
andq %rdx,%rdx # len > 0?
jg Loop # if so, goto Loop:偷工减料
我们知道iaddq指令会顺便set_cc,所以可以省掉一个andq %rdx,%rdx指令,把iaddq $-1, %rdx指令移动到jg loop上面。然后跑一遍!
60opts!!!
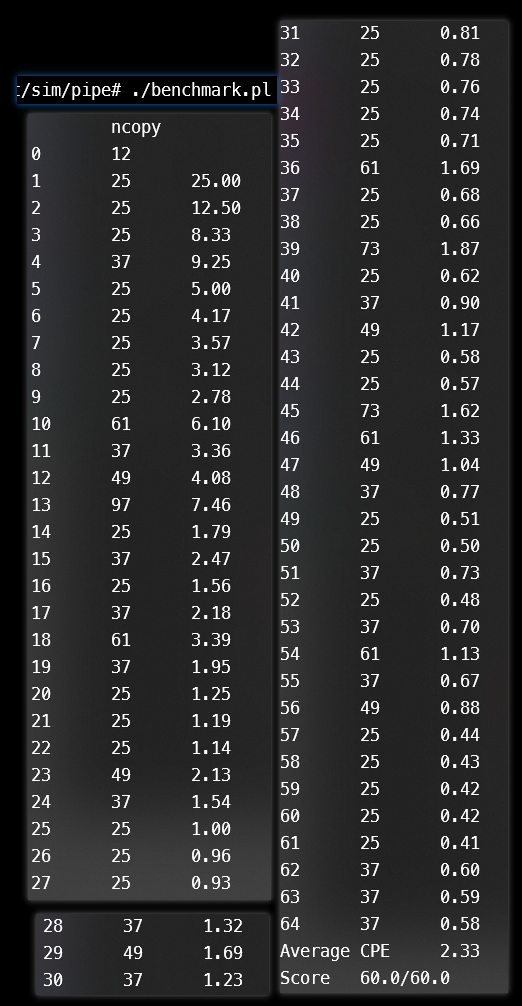
但这是虚假的!用sdrivers测一下就会得到以下结果
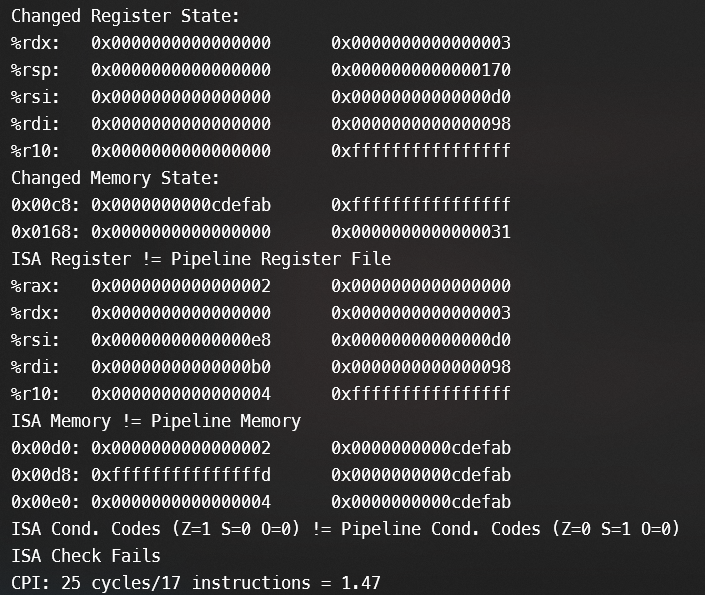
大脑瞬间宕机,思考好一会,发现自己在hcl里面没有对IADDQ改set_cc。
bool set_cc = (E_icode == IOPQ || E_icode== IIADDQ) && 改完后再次运行。
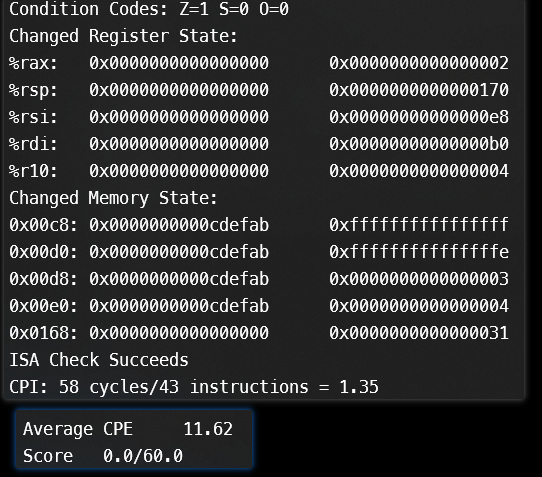
喜提零分!
pipe-full.hcl要能过../y86-code 和 ../ptest的测试,尤其是这点,benchmark不检查对错,如果psim有问题,benchmark可能会得到很低的CPE,误以为自己得了满分。
循环展开
二路展开
# You can modify this portion
# Loop header
iaddq $-2,%rdx
jl L0R1
Loop1 :
mrmovq (%rdi),%r8
rmmovq %r8,(%rsi)
andq %r8,%r8
jle Loop2
iaddq $1,%rax
Loop2:
mrmovq 0x8(%rdi),%r8
rmmovq %r8,0x8(%rsi)
andq %r8,%r8
jle step
iaddq $1,%rax
step:
iaddq $0x10,%rdi
iaddq $0x10,%rsi
iaddq $-2,%rdx
jge Loop1
L0R1:
iaddq $1,%rdx
je REM1
ret
REM1:
mrmovq (%rdi),%r8
rmmovq %r8,(%rsi)
andq %r8,%r8
jle Done
iaddq $1,%raxAverage CPE 9.69
Score 16.3/60.0
所以我们尝试多路展开,关于对余数的处理,我们可以采取多叉搜索树。
十路展开
对于余数[0~9]采取三叉搜索树,即L0R9分为L0R2和3和L4R9,L0R2又分为0,1,2,L4R9又分为L4R6,7,L8R9.
# You can modify this portion
# Loop header
iaddq $-10,%rdx
jl L0R9
Loop1 :
mrmovq (%rdi),%r8
rmmovq %r8,(%rsi)
andq %r8,%r8
jle Loop2
iaddq $1,%rax
Loop2:
mrmovq 0x8(%rdi),%r8
rmmovq %r8,0x8(%rsi)
andq %r8,%r8
jle Loop3
iaddq $1,%rax
Loop3:
mrmovq 0x10(%rdi),%r8
rmmovq %r8,0x10(%rsi)
andq %r8,%r8
jle Loop4
iaddq $1,%rax
Loop4:
mrmovq 0x18(%rdi),%r8
rmmovq %r8,0x18(%rsi)
andq %r8,%r8
jle Loop5
iaddq $1,%rax
Loop5:
mrmovq 0x20(%rdi),%r8
rmmovq %r8,0x20(%rsi)
andq %r8,%r8
jle Loop6
iaddq $1,%rax
Loop6:
mrmovq 0x28(%rdi),%r8
rmmovq %r8,0x28(%rsi)
andq %r8,%r8
jle Loop7
iaddq $1,%rax
Loop7:
mrmovq 0x30(%rdi),%r8
rmmovq %r8,0x30(%rsi)
andq %r8,%r8
jle Loop8
iaddq $1,%rax
Loop8:
mrmovq 0x38(%rdi),%r8
rmmovq %r8,0x38(%rsi)
andq %r8,%r8
jle Loop9
iaddq $1,%rax
Loop9:
mrmovq 0x40(%rdi),%r8
rmmovq %r8,0x40(%rsi)
andq %r8,%r8
jle Loop10
iaddq $1,%rax
Loop10:
mrmovq 0x48(%rdi),%r8
rmmovq %r8,0x48(%rsi)
andq %r8,%r8
jle step
iaddq $1,%rax
step:
iaddq $0x50,%rdi
iaddq $0x50,%rsi
iaddq $-10,%rdx
jge Loop1
# applying range checks to remainders
L0R9:
iaddq $7,%rdx # Compare with 3 (len + 10 - 3)
jl L0R2 # len < 3
jg L4R9 # len > 3
je Rem3 # len == 3
L0R2:
iaddq $2,%rdx # Compare with 1 (len + 3 - 1)
je Rem1 # len == 1
jg Rem2 # len == 2
ret # len == 0
L4R6:
iaddq $2,%rdx # Compare with 5 (len + 7 - 5)
jl Rem4 # len == 4
je Rem5 # len == 5
jg Rem6 # len == 6
L4R9:
iaddq $-4,%rdx # Compare with 7 (len + 3 - 7)
jl L4R6 # len < 7
je Rem7 # len == 7
L8R9:
iaddq $-1,%rdx # Compare with 8 (len + 7 - 8)
je Rem8 # len == 8
# dealing with remainders
Rem9:
mrmovq 0x40(%rdi), %r8
rmmovq %r8, 0x40(%rsi)
andq %r8, %r8
jle Rem8
iaddq $1, %rax
Rem8:
mrmovq 0x38(%rdi), %r8
rmmovq %r8, 0x38(%rsi)
andq %r8, %r8
jle Rem7
iaddq $1, %rax
Rem7:
mrmovq 0x30(%rdi), %r8
rmmovq %r8, 0x30(%rsi)
andq %r8, %r8
jle Rem6
iaddq $1, %rax
Rem6:
mrmovq 0x28(%rdi), %r8
rmmovq %r8, 0x28(%rsi)
andq %r8, %r8
jle Rem5
iaddq $1, %rax
Rem5:
mrmovq 0x20(%rdi), %r8
rmmovq %r8, 0x20(%rsi)
andq %r8, %r8
jle Rem4
iaddq $1, %rax
Rem4:
mrmovq 0x18(%rdi), %r8
rmmovq %r8, 0x18(%rsi)
andq %r8, %r8
jle Rem3
iaddq $1, %rax
Rem3:
mrmovq 0x10(%rdi), %r8
rmmovq %r8, 0x10(%rsi)
andq %r8, %r8
jle Rem2
iaddq $1, %rax
Rem2:
mrmovq 0x8(%rdi), %r8
rmmovq %r8, 0x8(%rsi)
andq %r8, %r8
jle Rem1
iaddq $1, %rax
Rem1:
mrmovq (%rdi), %r8
rmmovq %r8, (%rsi)
andq %r8, %r8
jle Done
iaddq $1, %raxncopy length = 988 bytes
Average CPE 8.39
Score 42.3/60.0
戳气泡
Y86-64处理器的流水线有 F(取指)、D(译码)、E(执行)、M(访存)、W(写回) 五个阶段,D 阶段才读取寄存器,M 阶段才读取对应内存值,注意我们在十路展开里面有大量的mr和rm对同一个寄存器进行操作,在中间有空余bubble,可以考虑用多个寄存器来存,来利用其中的bubble空余时间,代码如下
# You can modify this portion
# Loop header
iaddq $-10,%rdx
jl L0R9
Loop10:
#取值
mrmovq (%rdi),%r8
mrmovq 0x8(%rdi),%r9
mrmovq 0x10(%rdi),%r10
mrmovq 0x18(%rdi),%r11
mrmovq 0x20(%rdi),%r12
mrmovq 0x28(%rdi),%r13
mrmovq 0x30(%rdi),%r14
mrmovq 0x38(%rdi),%rcx
mrmovq 0x40(%rdi),%rbx
mrmovq 0x48(%rdi),%rbp
#写值
rmmovq %r8,(%rsi)
rmmovq %r9,0x8(%rsi)
rmmovq %r10,0x10(%rsi)
rmmovq %r11,0x18(%rsi)
rmmovq %r12,0x20(%rsi)
rmmovq %r13,0x28(%rsi)
rmmovq %r14,0x30(%rsi)
rmmovq %rcx,0x38(%rsi)
rmmovq %rbx,0x40(%rsi)
rmmovq %rbp,0x48(%rsi)
#先判断一下
andq %r8,%r8
jle judge0
iaddq $1,%rax
judge0:
andq %r9,%r9
jle judge1
iaddq $1,%rax
judge1:
andq %r10,%r10
jle judge2
iaddq $1,%rax
judge2:
andq %r11,%r11
jle judge3
iaddq $1,%rax
judge3:
andq %r12,%r12
jle judge4
iaddq $1,%rax
judge4:
andq %r13,%r13
jle judge5
iaddq $1,%rax
judge5:
andq %r14,%r14
jle judge6
iaddq $1,%rax
judge6:
andq %rcx,%rcx
jle judge7
iaddq $1,%rax
judge7:
andq %rbx,%rbx
jle judge8
iaddq $1,%rax
judge8:
andq %rbp,%rbp
jle step
iaddq $1,%rax
step:
iaddq $0x50,%rdi
iaddq $0x50,%rsi
iaddq $-10,%rdx
jge Loop10
# applying range checks to remainders
L0R9:
iaddq $7,%rdx # Compare with 3 (len + 10 - 3)
jl L0R2 # len < 3
jg L4R9 # len > 3
je Rem3 # len == 3
L0R2:
iaddq $2,%rdx # Compare with 1 (len + 3 - 1)
je Rem1 # len == 1
jg Rem2 # len == 2
ret # len == 0
L4R6:
iaddq $2,%rdx # Compare with 5 (len + 7 - 5)
jl Rem4 # len == 4
je Rem5 # len == 5
jg Rem6 # len == 6
L4R9:
iaddq $-4,%rdx # Compare with 7 (len + 3 - 7)
jl L4R6 # len < 7
je Rem7 # len == 7
L8R9:
iaddq $-1,%rdx # Compare with 8 (len + 7 - 8)
je Rem8 # len == 8
# dealing with remainders
Rem9:
mrmovq 0x40(%rdi), %r8
rmmovq %r8, 0x40(%rsi)
andq %r8, %r8
jle Rem8
iaddq $1, %rax
Rem8:
mrmovq 0x38(%rdi), %r8
rmmovq %r8, 0x38(%rsi)
andq %r8, %r8
jle Rem7
iaddq $1, %rax
Rem7:
mrmovq 0x30(%rdi), %r8
rmmovq %r8, 0x30(%rsi)
andq %r8, %r8
jle Rem6
iaddq $1, %rax
Rem6:
mrmovq 0x28(%rdi), %r8
rmmovq %r8, 0x28(%rsi)
andq %r8, %r8
jle Rem5
iaddq $1, %rax
Rem5:
mrmovq 0x20(%rdi), %r8
rmmovq %r8, 0x20(%rsi)
andq %r8, %r8
jle Rem4
iaddq $1, %rax
Rem4:
mrmovq 0x18(%rdi), %r8
rmmovq %r8, 0x18(%rsi)
andq %r8, %r8
jle Rem3
iaddq $1, %rax
Rem3:
mrmovq 0x10(%rdi), %r8
rmmovq %r8, 0x10(%rsi)
andq %r8, %r8
jle Rem2
iaddq $1, %rax
Rem2:
mrmovq 0x8(%rdi), %r8
rmmovq %r8, 0x8(%rsi)
andq %r8, %r8
jle Rem1
iaddq $1, %rax
Rem1:
mrmovq (%rdi), %r8
rmmovq %r8, (%rsi)
andq %r8, %r8
jle Done
iaddq $1, %raxncopy length = 988 bytes
Average CPE 7.65
Score 57.1/60.0
最后得分:57.1差不多就这样吧.
小记
这个lab做的挺草率的,书都没怎么看,几乎算是面向题目的学习,lab的难度也确实不高,最后partc就以57.1分收尾了,以后想折腾以后的事,感觉还是有不少能戳气泡,调整的空间,但现在3月29号,要去做字符串,图论,备战校赛了,lab先搁浅搁浅。累的时候再做做emmmm



